Seeds at Scale
6 years ago by Dr. rer. nat. Michael Röder
In our previous post, we looked into the details of random number generators (RNGs) with a focus on the default implementation in Java (the Random class). We pointed out that an RNG works deterministically and can be imagined to be walking on a cycle of numbers with a deterministic order—making the numbers returned by the RNG pseudo-random. In addition, we pointed out the practical usefulness of seed values. In this blog post, we want to dig deeper into some practical implications of using seed values in scalable programs.
Nowadays, processing large amounts of data becomes more and more important. At the same time, the hardware used to process all the data typically relies on (one or several) multicore CPUs. To make use of the whole capacity of this type of hardware, programs need to make use of multiple threads (or even multiple, distributed processes). In a lot of cases, these threads make use of RNGs and—as pointed out in the previous blog post—all of them should be initialized with a seed value. However, using the same seed value for all threads would mean that all threads ended up with exactly the same random numbers. Letting the program take a single seed value for each thread would have other disadvantages, e.g., the program couldn’t decide by itself whether it needs to create additional threads if all given seed values have been used. The solution is a generator for seed values. This generator should be able to generate a large amount of good seed values in a deterministic, repeatable way, based on a single, given seed value.
Pseudo-random seeds
A first idea to create a seed generator could be to use a “Master RNG”, which is used to generate all the seed values for the other RNGs. However, since a lot of RNG implementations typically rely on the concept of a linear congruential generator, this would lead to all RNGs creating nearly the same numbers.
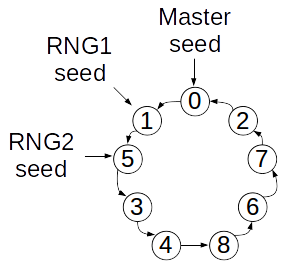
In the example, 0 is chosen as seed for the “Master RNG”. Following the logic of a linear congruential generator, this RNG would calculate the next pseudo-random number—in this example the 1—and use it as seed for the second pseudo-random number―the 5. These two would be used as seeds for the two example RNGs. This leads to both RNGs starting at almost the same position on the ring of numbers. RNG2 would simply be one step ahead of RNG1. This is a strong relation that is created between these two RNGs, which would lead to biased random numbers and, hence, to biased results.
The default implementation in Java has a different behavior. It never returns its “internal” seed—i.e., in the example above, it would not return 1. Because the class works internally with 48 bit numbers, it transforms them before returning a result. This transformation allows only 32 bit numbers to be returned, i.e., 16 bits of its internal number never leave the class. Hence, the effect described above cannot be directly seen when implementing it in Java using the default Random class. In general, it is not recommended for linear congruential generators.
Sequential seeds
A better strategy, which works with all linear congruential generators, is to start with a seed and increment it linearly. Since random number generators try to avoid such behavior (i.e., the behavior of a simple linear function that produces numbers not recognized as being random), it is very likely to get a large number of RNGs starting at different positions of the number cycle. The easiest way to achieve such a linear increment is to increment the given seed by 1 each time a seed is needed to initialize a new RNG.
Although this approach is sound, it may need to be adapted to the RNG implementation. In Java, the Random class mainly relies on the highest 48 bits of a seed. The higher bits of a pseudo-random number generated by a linear congruential generator are known to be “more random” than the lower bits. Since the generator will use a generated number as internal seed for the next number, it makes sense to rely on the number’s highest bits. However, in practice, seeds can be defined by humans and humans tend to use short seeds instead of 48 or 64 bit numbers. This can lead to bad behavior of the Java Random class, as observed when executing the following piece of code.
public static void main(String[] args) {
for (int i = 0; i < 20; ++i) {
System.out.println((new Random(i)).nextInt(32));
}
}
The program initialises 20 RNGs with consecutive seeds (0 to 20), and uses each of them to sample an integer from the range [0, 31]. Surprisingly, all 20 RNGs return 23. This is caused by a coincidence of two implementation details: 1) the seeds are small numbers, and 2) the boundary for the chosen integer is a multiple of 2. The first point leads to the situation that the RNGs start with an internal number with the same numbers in their highest bits. The second point forces the RNG to directly return the highest bits by shifting the number of necessary bits.
It should be noted that this problem only exists for the first number that is drawn with these RNGs. The following numbers will be different. However, this issue has already led to bad behavior in one of our simulations since both requirements for this issue are not uncommon. 1) Humans tend to use numbers they use often, which are typically small numbers. 2) Humans (especially computer scientists) tend to scale parameters by 2, making parameters very likely to be multiples of 2.
This situation can be avoided by various solutions that mainly change the sequentially generated seeds so that their higher bits differ from seed to seed. Our best solution is to simply reverse the order of the bits. The following piece of code does show a better result.
public static void main(String[] args) {
for (int i = 0; i < 20; ++i) {
System.out.println(
(new Random(Integer.reverse(i))).nextInt(32));
}
}
Short Summary
Summarizing the insights from above leads to the following recommendations:
- Whenever scalability is answered by multithreading (or even multiprocessing), creating seeds for the different, parallelly-used RNGs is an important topic.
- Relying on pseudo-random numbers as seeds is not recommended, since it can lead to producing nearly the same random numbers in all threads.
- Creating seeds sequentially can be a solution if: 1) The implementation is tested thoroughly to cover corner cases and 2) specific characteristics of the used RNG implementation are taken into account.