OPAL Open Data Hackathon
5 years ago by Adrian Wilke
On 6 April 2020, the OPAL Open Data Hackathon took place in the form of a remote event. It focused on mobility data, for which participants developed ideas and software solutions. For this purpose, information on possible tasks, data formats and data collections were provided on the Hackathon website, allowing the participants to explore the Semantic Web and description languages on their own. Among the solutions submitted, two winners were chosen.
Winner: Spatial visualization of available datasets
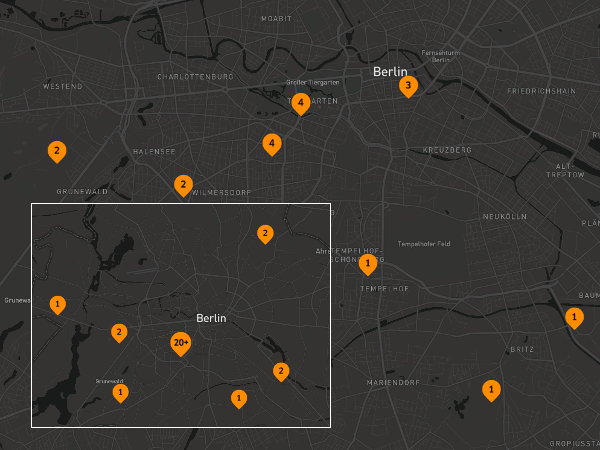
Nikit Srivastava developed his solution Show-Geo for displaying data records on a map. For this purpose, a software component queries datasets and the associated spatial data in DCAT format using SPARQL. The processed related polygons are provided for online access through webservices via a REST interface. A second component then manages the preparation of data for displaying in web browsers. Users have access to worldwide data on a map, showing the respective number of available datasets in different geographical regions. Depending on the zoom level of the map, the number of datasets is displayed in clusters. Additional technologies used are Java, Spring Boot, Apache Jena, JavaScript, Node, React (Angular in development) and Mapbox.
Winner: Classification of datasets for category assignment
Ana Alexandra Morim da Silva contributes Theme-Classify, a method for classifying datasets. Actual data collections contain datasets, which are partly not assigned to a category. In order to automatically assign categories, the description of dataset texts is analyzed. Thereby, it is assumed that similar words are used in descriptions of datasets of the same category. Based on this assumption, the system determines which word combinations of already categorized datasets are statistically most similar to an uncategorized dataset.
In the contribution, a SPARQL query is used to determine names, descriptions and categories of records. Afterwards the data is split into training and test data. After a normalization of the words and removal of stopwords, vectors are computed. TF-IDF (term frequency and inverse document frequency), and decision trees are used in the analysis. Users can specify whether J48 or Naive Bayes is used and choose between the size of n-grams. Finally, an evaluation of the correctness of the allocations is provided. The developed software uses Java, WEKA, Apache Jena, SPARQL and Stanford NLP, among others.
Closing of the event
We sincerely thank all participants. A certificate of participation will be provided for all students who have submitted a Hackathon result. The two winners will also be sharing a prize, preferably in the form of Hasentalers, to support the local economy in Paderborn. Links to Open Data for the Paderborn region can still be found on the website; for potential use at a future event. If you have any questions about the event, please contact Adrian Wilke, details are available on the DICE website. This event has been supported by the German Federal Ministry of Transport and Digital Infrastructure (BMVI) in the OPAL project (no. 19F2028A).