Benchmarking Linked Data processing systems
Benchmarking systems is vital to data science. Benchmark results can reveal strengths and weaknesses of different approaches and can be used as guidance for further development. To this end, we are interested in benchmarking different systems with our benchmarks using the benchmarking frameworks we have.
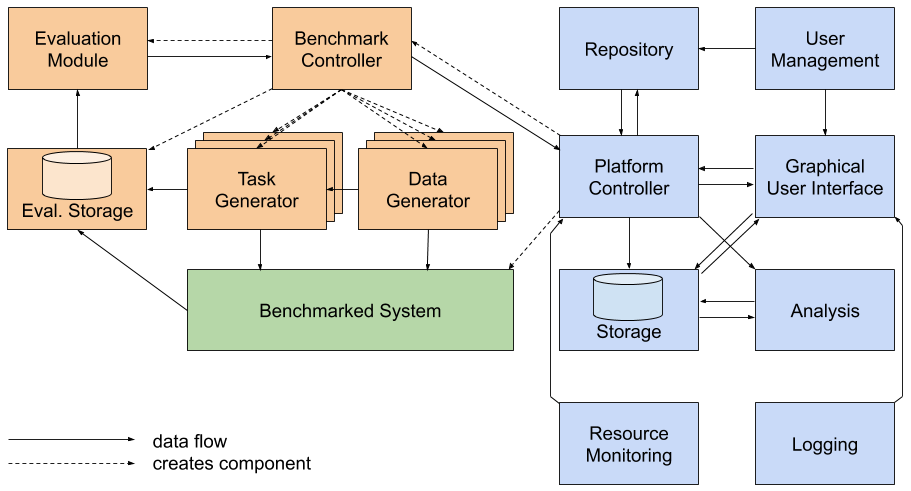
There are different possibilities, what type of system can be benchmarked. A good example is the benchmarking of triple stores on our Big Linked Data benchmarking platform HOBBIT. The task of the student is to take an existing system (e.g., a triple store) and write a system adapter for it to enable the benchmarking of the system (the green box in the figure above). Example triple stores for which no adapter is available are:
- TripleBit
- RDF-3X
- Tentris
- Blazegraph
- Fuseki
- GraphDB
- TriAD (distributed store)
The task of the student would be to write the system adapter for the triple store. This Mainly includes the implementation of the API of the benchmark/benchmarking framework on the one side and the implementation of the system's API on the other side.
It should be noted, that this topic is not restricted to triple stores and *not restricted to the HOBBIT platform. It is only used as an example. We have different benchmarking frameworks with different benchmarks for different types of systems covering all steps of the Linked Data lifecycle. This includes:
- Knowledge Extraction and its subtypes (e.g., Relation Extraction, Entity Linking, etc.)
- Triple Stores
- Question Answering
- Fact Checking
Related projects:
- Benchmarking frameworks: