Quiz game with explainable results
Evaluating different approaches is vital to data science. The gathered evaluation results can reveal strengths and weaknesses of different approaches and can be used as guidance for further development. However, especially if an evaluation provides a researcher with large amounts of results, analysing them manually can become a challenging task. A solution to this could be an approach that is able to explain in which cases an evaluated approach succeeds and in which cases it fails. The figure below shows this concept for an example of a classifier that should identify whether a given picture shows a cat (left class) or not (right class).
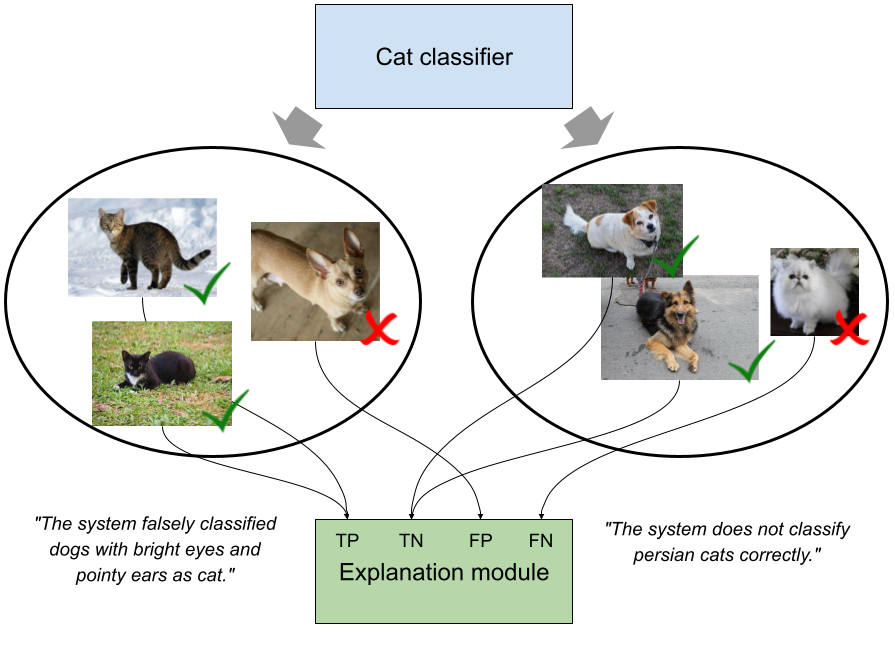
The goal of Explainable Benchmarking is to provide explanations as those in the figure above, i.e., explanations for cases in which an evaluated system performs good or not. The goal of this thesis is to provide a small demonstrator that shows to an audience what explainable benchmarking means. To this end, we would like to combine it with a game. The user plays the game and receives a summary of their performance. The summary is then generated as if the user would be an approach for which we would like to get explanations.
The game should be a quiz. The questions for the quiz should be generated based on a knowledge base (e.g., DBpedia or Wikidata). Similar to previous approaches like ASSESS or Clover Quiz, we generate multiple choice questions by using statements from the knowledge base. The chosen statements (s,p,o) represent the correct answer. We generate wrong answers (s,p,o') by choosing o' with a high similarity to o. The similarity can be measured within an knowledge graph embedding model. Based on the correctly and wrongly answered questions, we can generate explanations for the player's result using class expression learning (e.g., using Ontolearn).
The final goal is to submit the final work to the demo session of a conference (after the thesis is done) and make it easier to explain the concept of explainable benchmarking to people.